15. Training and Testing on Different Distributions
2023. 9. 14. 17:51ㆍGoogle ML Bootcamp/3. Structuring Machine Learning Projects
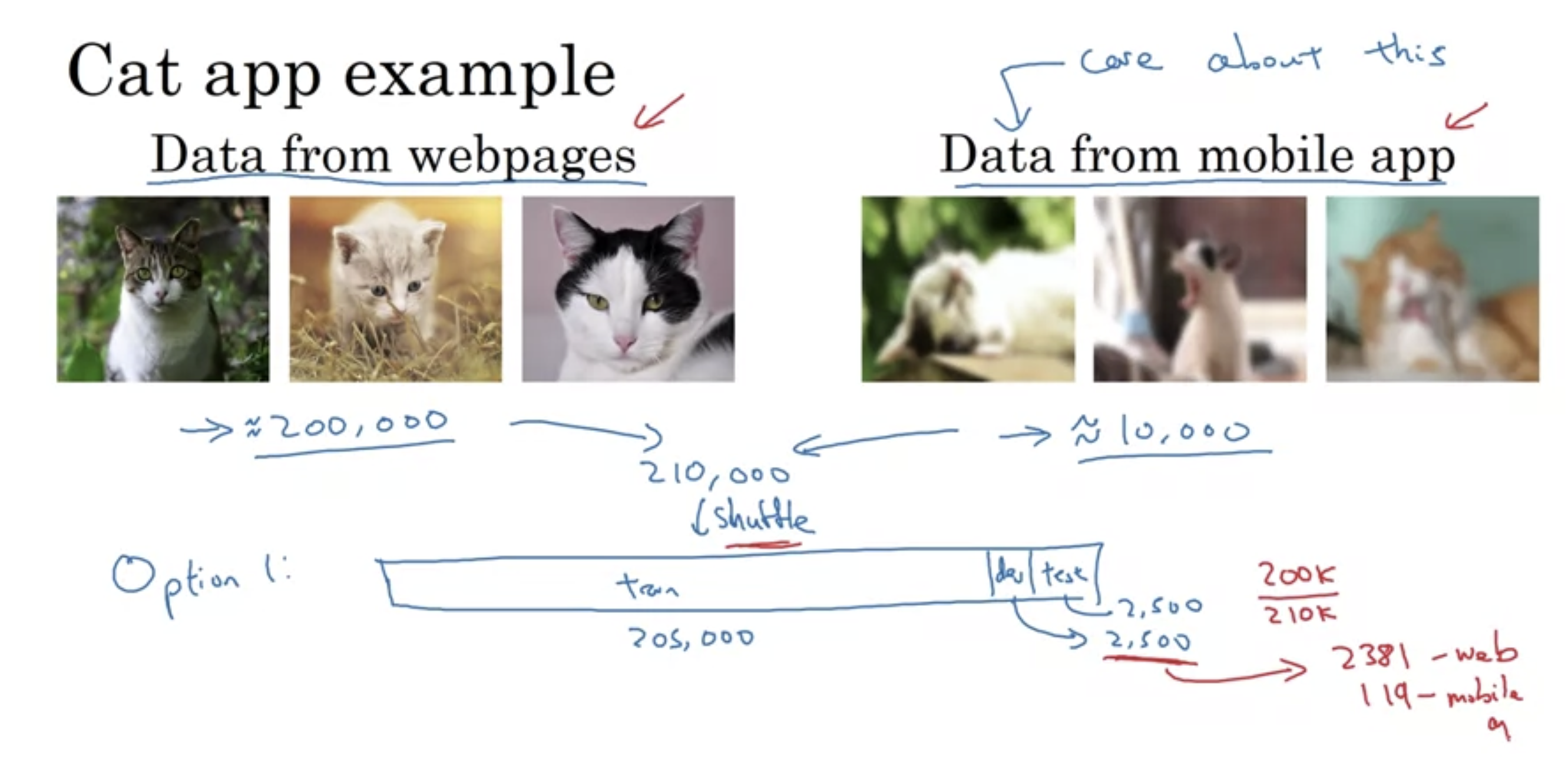
장점 : train/dev/test 모두 같은 분포를 가지게 한다.
단점 : 학습 시 new data의 비율이 상당히 낮기 때문에 거의 무시되고 original data의 분포를 잘 맞추는 경향으로 모델이 학습된다.
문제는 실제 어플리케이션에서는 new data와 같은 blurry이미지가 대부분 주어지기 때문에 저걸 더 잘 맞춰야한다는 점이다.

근데... train과 dev/test 분포가 다른데 학습이 잘 되고 성능이 괜찮을까? - 다음 강의에 설명하도록 한다.
- dev test에 대해 loss가 학습 과정에서 train과 다르게는 어떻게 작용하는지 단계별로 알아봐야할 것 같다.
'Google ML Bootcamp > 3. Structuring Machine Learning Projects' 카테고리의 다른 글
| 17. Addressing Data Mismatch (0) | 2023.09.15 |
|---|---|
| 16. Bias and Variance with Mismatched Data Distributions (0) | 2023.09.15 |
| 14. Bulid your First System Quickly, then Iterate (0) | 2023.09.14 |
| 13. Cleaning Up Incorrectly Labeled Data (0) | 2023.09.14 |
| 12. Error Analysis (0) | 2023.09.14 |