2024. 4. 3. 13:26ㆍ기술 면접/데이터베이스
빅데이터란?
대량의 정형 또는 비정형 데이터를 의미하고, 기존의 관리 도구로는 어려운 규모와 다양성을 가지고 있는 데이터를 의미합니다. 마케팅 분석에 따른 추천 시스템, 혹은 예측 분석 등 다양한 분야에서 빅데이터를 분석하여 비즈니스 가치를 창출할 수 이씁니다.
대용량 데이터 관리 : parition & combine!
문제점: 병목현상(deadlock) 발생
해결방안: 동기화 메커니즘(Communication between workers, Access to shared resources) 활용
**동기화 메커니즘:
1) Programming model 활용 : Thread를 활용한 shared memory기법 or Message Passing 기법 활용
2) Design Patterns : Master-slaves 구조 / Producer-Consumer flows 구조 / Shared Work Queues 구조
**결국 메모리(하드웨어) 성능 향상이 아닌 데이터 처리 구조를 이용하여 빅데이터 처리를 실행 → Hadoop 등장.
빅데이터 처리 도구
1) Hadoop
2) Pyspark
Hadoop : map-reduce 기법(=분산 파일 시스템)
문제점: map 과정에서 reduct까지 많은 복사본을 가져야 하는 문제점 발생
해결방안: map-combine-reduce를 통해 최적화 달성.
한계점
1) 비정형 데이터에 적용할 수 없다
2) 실시간 처리 불가능하다
3) 프로그래밍 복잡하다
4) 응용이 제한적이다 : batch 프로세싱(미리 주소를 인덱싱 해놓는 방법으로 특수 목적 프레임에만 사용됨)을 사용
5) 매 반복마다 Disk에 저장한다.
**Disk에 접근하는 작업은 매우 무거운 작업이므로 중간결과를 메모리에 저장하는 spark가 등장!
Spark: 1 Matser - N slaves 구조(1 Driver - N Executor) 분산 파일 시스템
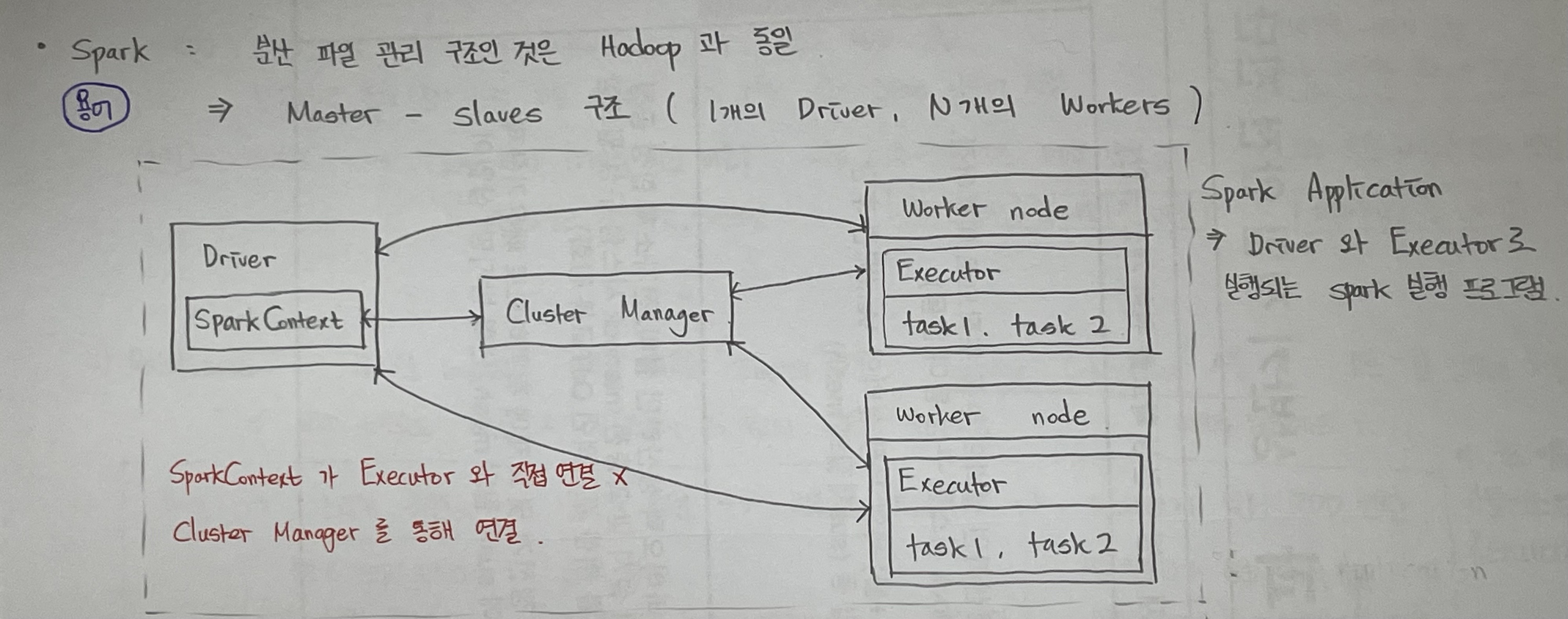
- Driver: Spark Application 생명 주기 관리자. SparkContext 객체를 생성하여 Clutser Manager와 연결.
- Cluster Manager: Spark Application의 resource를 효율적으로 분배하여 task가 실행되는 worker node를 관리
- Executors: Driver가 할당한 task를 수행하여 결과를 반환
**핵심: 분산 메모리 저장 Not Disk!
Spark 특징
1) In-memory 연산: HDFS(HaDoop File System)에 비해 메모리에서 100배, 디스크에서 10배 빠르다.
2) 여러 언어 지원 : Python, R, SQL, Scala, Java 등
3) 고급 분석 지원 : SQL Query, Streaming, ML, Graph 등 여러 라이브러리 지원
Spark의 데이터 표현
1) RDD(Resilient Distributed Datasets): transformation & action
기본명령어(sc = pyspark.SparkContext()) → pyspark 라이브러리 활용
- data = sc.textFile(), data = sc.parallelize() : 데이터 load / 데이터 생성 명령어
- data.collect() : 데이터 read 명령어
- transformation 연산: data.map() , data.filter() : 주로 lambda 함수를 활용하여 수행.
- action 연산: data = data.reduce() : 파티션 수 만큼 진행하고 결과값을 반환
- data.saveAsTextFile() : 최종 생성된 RDD 저장
한계점:
a. 메모리나 디스크 저장공간이 충분하지 않으면 작동하지 않음(transformtation 연산이 매번 새로운 RDD 생성)
b. GC(Garbage Collection) 사용. 즉 메모리 오버헤드가 발생할 수 있음
c. 내장된 최적화 엔진이 존재하지 않아 사용자가 직접 최적화를 진행해야함.
2) Dataframe: 구조화된 데이터를 다루기 위한 데이터 구조로 GC를 사용하지 않아 메모리 오버헤드가 발생하지 않음.
- RDBMS와 유사한 table형태의 spark 자료 구조.
- SQL 사용가능, RDD와 상호변환 가능.
- 여러 환경에서 빗스한 속도를 가지며, JSON data 또한 dataframe으로 변환 가능
**Dataframe: 카탈리스트 옵티마이저 구조 = RDD에 비해 속도 향상
- 카탈리스트 옵티마이저란? : 분석 → 논리적 최적화 → 물리적 플랜 → 코드 생성 구조를 의미함.

기본 명령어
- df = spark.read.json() : 카탈리스트 옵티마이저를 통해 빠르게 RDD를 생성하여 반환해줌
- df.select().filter() / spark.sql().show() : SQL 문과 같이 조건절 푸시다운으로 인한 RDD 생성
- df.distinct() : 중복 행 제거 / df.dropDulicates(['column1']) : 해당 column 기준 중복 값을 가지는 행 제거
Spark streaming:
스트리밍 데이터 특징:
- 주로 비즈니스적 수요가 많은 수천개의 원본 데이터에서 생성되는 데이터로 이상거래, 이상 센서 징후 탐지에 사용됨.
- 뿐만 아니라 SQL 등 툴을 사용하여 비즈니스 분석이 가능하다.
스파크 스트리밍: 실시간 데이터 분석을 위한 스파크 컴포넌트로 다양한 언어와 라이브러리를 지원한다.
필요성
1) 스트리밍 ETL(Extraction,Transform,Load): 데이터가 다운스트림으로 들어가기 전 정제,집계를 수행
2) 트리거 : 이상 행위에 대한 실시간 탐지 및 다운스트림 액션
3) 데이터 enrichment : 풍부한 데이터 분석을 위한 실시간 데이터 조인
4) 복잡한 세선과 지속적인 학습 : 여러 데이터셋이 합쳐진 실시간 데이터들을 지속적으로 분석 및 업데이트
**구조적 스트리밍: 물리적 플랜, 비용 옵티마이저를 이용해 여러 물리적 플랜 중에서 최적의 물리적 플랜을 찾음
Spark Machine Learning
대량의 데이터를 빠르게 전처리할 수 있음.
다만 library 업데이트가 느리고 대중적인 몇몇 ML 알고리즘만 구현되어 있음.
- Transformer : dataframe을 input으로 받아들이고 하나 이상의 column을 추가하여 새로운 dataframe을 반환
- Estimator : dataframe에서 매개변수 학습, 변환기인 ML model 반환
- pipelines(Transformer + Estimator) : 일련의 변환기와 추정기를 단일 모델로 구성
'기술 면접 > 데이터베이스' 카테고리의 다른 글
| 데이터베이스 기술 면접 기본 개념(1) (0) | 2024.04.02 |
|---|