4. Regularization
2023. 9. 10. 16:10ㆍGoogle ML Bootcamp/2. Improving Deep Neural Networks

L1 정규화의 경우 w will be sparse.
- 이는 모델 압축에 도움이 될 순 있지만 모델 압축이 목적이 아니라면 굳이..
보통의 경우 L2 정규화를 사용함을 기억하자.
Cost function에 대하여 L 개의 layer에 존재하는 W에 대해 정규화를 수행한다고 할 때
- W[l].shape : (n[l], n[l-1])
- 따라서 W[l] ** 2 = sum(sum( w(ij)**2 )) - L2 norm
- 이를 Frobenius norm이라고 부른다. 관례이므로 그냥 기억하자. L2 norm이 아니더라.
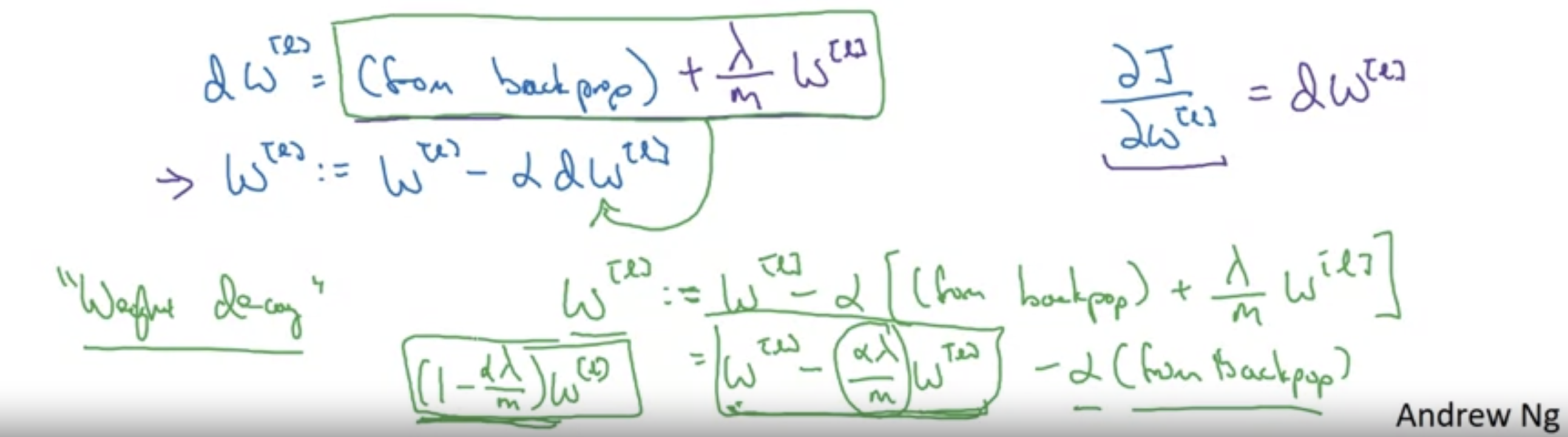
기존에 learning rate * dW 만큼 update 된데에 비해 더 크게 변하게됨
- 정규화 과정이 없을 때 비해 수식을 전개해보았을 때 (1- a*람다 /m) W[l]이므로 결국 W[l]보다 조금 작아졌음을 볼 수 있다.
- learning rate, 람다, m 모두 양수.
- Gradien Descent를 관찰했을 때, W는 감소하는 방향으로 진행되므로 정규화를 Weight decay(가중치 감쇠)라고 부른다.
'Google ML Bootcamp > 2. Improving Deep Neural Networks' 카테고리의 다른 글
| 6. Dropout Regularization (0) | 2023.09.10 |
|---|---|
| 5. Why Regularization Reduces Overfitting (0) | 2023.09.10 |
| 3. Basic recipe for machine learning (0) | 2023.09.10 |
| 2. Bias / Variance (0) | 2023.09.10 |
| 1. Train / Dev / Test sets (0) | 2023.09.10 |