25. The Problem of Local Optima
2023. 9. 11. 16:04ㆍGoogle ML Bootcamp/2. Improving Deep Neural Networks

사실 딥러닝 초반에 Local optimal point에 갇히게 되는 경우를 걱정하곤 했다.
하지만 20,000 차원의 input이 주어졌을 때, 왼쪽 그래프에서 optimal point란 모든 변수가 일정 구간에서 convex function 이여야하며 그때 기울기가 0인 지점인데 그럴 확률은 2**(-20000) ~= 0 이다.
따라서 optimal point보다는 saddle point(안장점)이라고 표현하곤 한다.
- local optimal point가 발생할 확률은 0에 가까운데 그렇다면 뭐가 문제일까?
The problem is plateaus!!
- 미분이 오래동안 0에 가까운 영역을 의미.
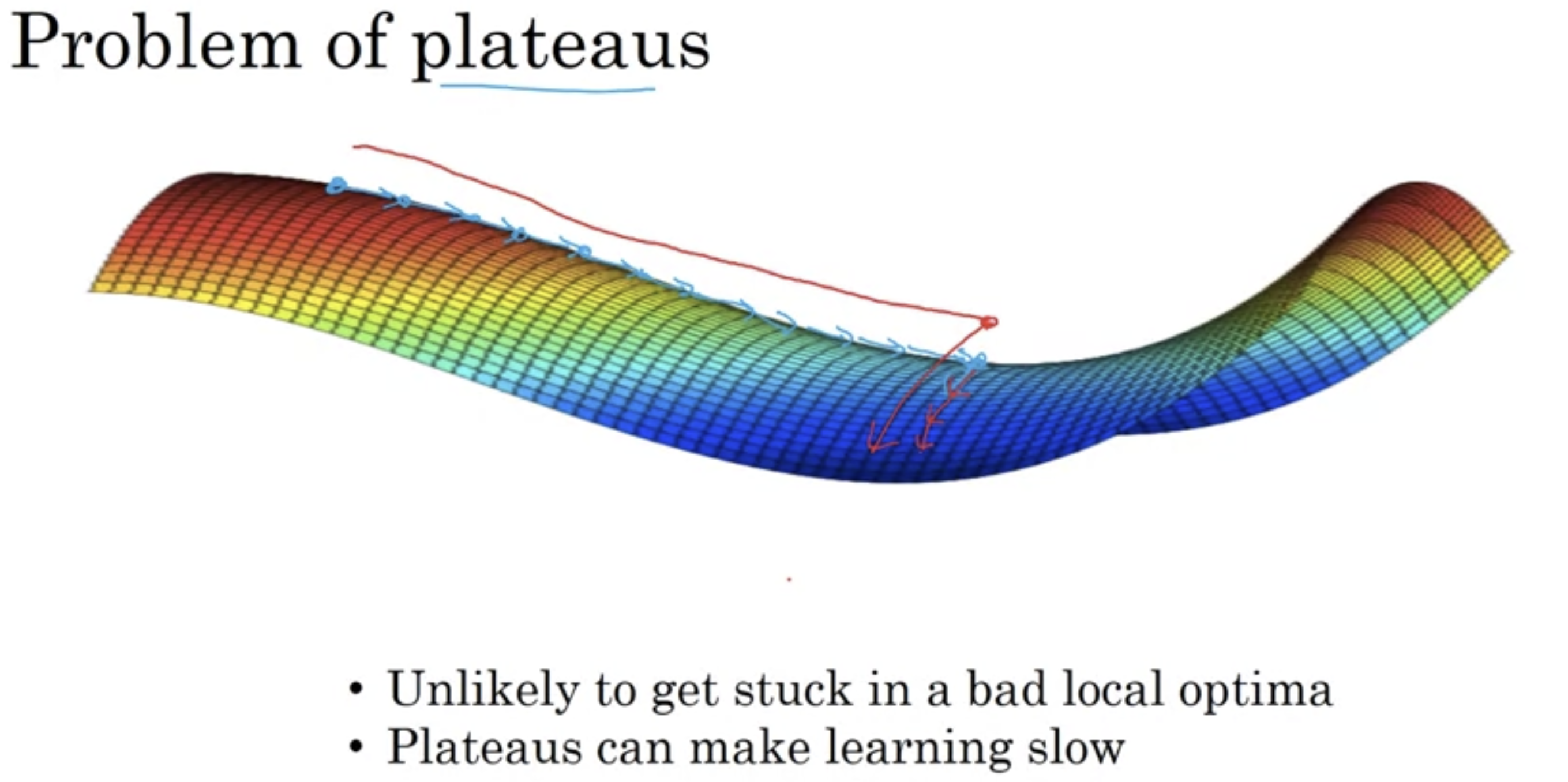
Wight 별 학습량을 다르게 하여 plateaus 구간을 빠르게 빠져나올 수 있도록 Momentum, RMSprop, Adam과 같은 알고리즘이 도와줄 수 있다.
'Google ML Bootcamp > 2. Improving Deep Neural Networks' 카테고리의 다른 글
| 27. Using an Appropriate Scale to pick Hyper parameters (0) | 2023.09.12 |
|---|---|
| 26. Tuning Process (0) | 2023.09.12 |
| 24. Learning Rate Decay (0) | 2023.09.11 |
| 23. Adam Optimization Algorithm (0) | 2023.09.11 |
| 22. RMSprop (0) | 2023.09.11 |