2023. 9. 15. 14:04ㆍGoogle ML Bootcamp/4. Convolutional Neural Networks
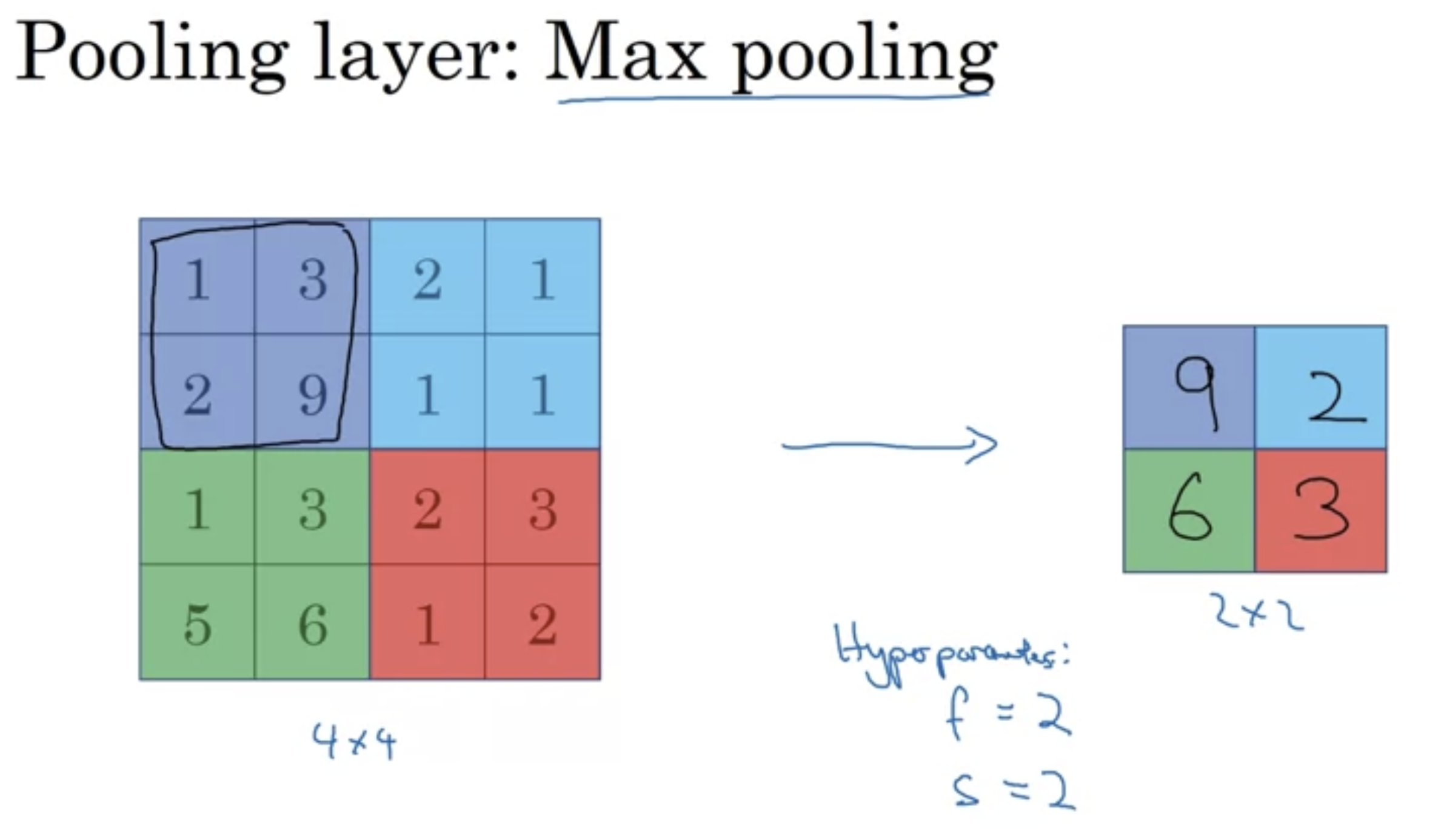
Max pooling 왜 하나?
- 한 특성(feature like 수염, 눈 etc...)이 필터의 한 부분에서 검출(detect)되면 최대값을 남긴다(keep the high number)
- 특성이 검출되지 않은 부분에서도 최대값을 남기긴 하지만 여전히 작은값 (예시에서는 2,3)으로 남게 된다.
이때 max pooling filter에 적용되는 filter size, stride, padding 등 모두 hyperparameter (no parameter, no train)
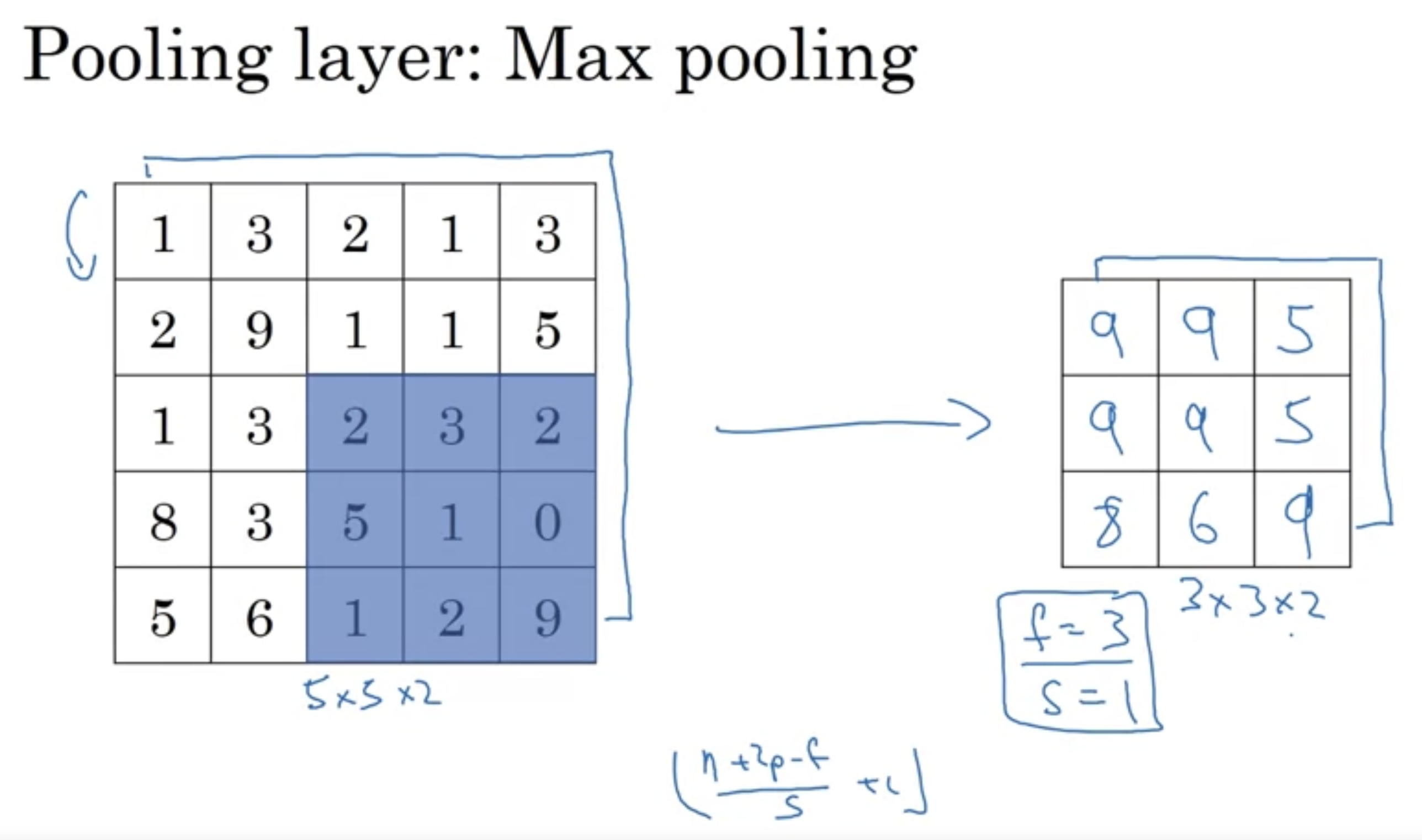
pooling filter : 2D.
- 즉 각 채널에 개별적으로 적용되는 것.
- Max 값을 취하는 방식이기 때문에 parameter가 따로 존재하지는 않는다. stride, filter size만 hyperparameter만 존재할뿐.
max pooling 외에도 average pooling, min pooling도 존재.
pooling : 결국 Image의 크기를 줄여 학습을 빨리 진행하는 효과를 가져온다.(=regularization 효과)
- 애초에 image의 크기를 줄이기 위함인데 padding을 도입할 필요는 없다.
- padding 자체가 모서리 pixel의 영향력이 다른 pixel에 비해 떨어지기 때문인데 pooling은 모든 pixel이 한번씩만 참여하므로 padding이 필요 없다.
**중요 : pooling 은 backward propagation시 학습할 parameter가 존재하지 않는다.**
'Google ML Bootcamp > 4. Convolutional Neural Networks' 카테고리의 다른 글
| 11. Why Convolutions? (0) | 2023.09.15 |
|---|---|
| 10. CNN Example (0) | 2023.09.15 |
| 8. Simple Convolutional Network Example (0) | 2023.09.15 |
| 7. One Layer of a Convolution Network (0) | 2023.09.15 |
| 6. Convolutions Over Volume (0) | 2023.09.15 |